Inclure des informations texte dans des données numérisées
Vous pouvez utiliser la fonction d'OCR pour inclure les informations texte dans le document numérisé sans traiter les données sur votre ordinateur.
![]()
Pour en savoir plus sur les unités en option requises pour cette fonction, reportez-vous à Pour les utilisateurs débutants.
La fonction OCR peut traiter des textes jusqu'à 40 000 caractères par page.
La fonction OCR peut reconnaître les langues suivantes :
Anglais, Allemand, Français, Italien, Espagnol, Néerlandais, Portugais, Polonais, Suédois, Finnois, Hongrois, Norvégien, Danois, Japonais.
Cette fonction prend en charge les types de fichier suivants : [PDF], [PDF Haute compr.] et [PDF/A].
Si [Noir&Blanc : Photo] est sélectionné dans l'onglet [Type d'original] sous [Paramètres numérisation] quand les originaux sont numérisés, le texte est numérisé en nuances de gris et les caractères ainsi que le haut et le bas de la page peuvent ne pas être facilement reconnaissables. Si la précision de l'OCR est prioritaire sur la qualité de l'image, sélectionnez [Noir&Blanc : Texte] dans l'onglet [Type d'original] sous [Paramètres numérisation] lors de la numérisation de l'original.
Vous ne pouvez pas utiliser la fonction OCR dans les cas suivants :
[TIFF/JPEG] ou [TIFF] est sélectionné comme type de fichier.
[100 dpi] est sélectionné comme résolution.
Lorsque la liste de destinations WSD ou DSM est utilisée.
![]() Lors de l'utilisation de l'application Scanner
Lors de l'utilisation de l'application Scanner
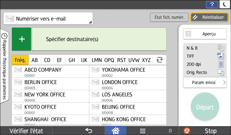
En ce qui concerne l'utilisation de l'écran de l'application, voir « Écran [Scanner] (standard) ».
![]() Lors de l'utilisation de l'application Scanner (Classique)
Lors de l'utilisation de l'application Scanner (Classique)
Pour plus d'informations sur l'utilisation de la fonction de numérisation classique, voir Procédure d'intégration d'informations de texte dans les données numérisées (classique).